-
<심화 프로젝트> 와인 가격 예측 - 2내일배움캠프(데이터 분석 부트캠프 1기)/팀프로젝트 2024. 2. 22. 15:27
[와인 가격 예측 -1]에서 이어짐
링크 : https://jinhyunbae.tistory.com/159
<심화 프로젝트> 와인 가격 예측 - 1
개요 프로젝트 모델링 과정의 개요는 아래 그림과 같다. 우선 데이터에 대해 EDA와 전처리를 진행하고 파생변수를 생성했다. 그리고 전처리된 데이터로 모델링 과정을 진행하였다. 첫 번째로 모
jinhyunbae.tistory.com
모델링
앙상블(Ensemble) 모델

앙상블 모델이란 여러 개의 개별 모델을 조합하여 최적의 모델로 일반화하는 머신러닝 방법이다.
대표적인 방법으로는 배깅과 부스팅이 있다. 본 프로젝트에서는 배깅을 활용한 대표적인 알고리즘인
RandomForest의 Regression모델과 XGBoost의 Regression 모델을 사용하였다.
RandomForest Regressor
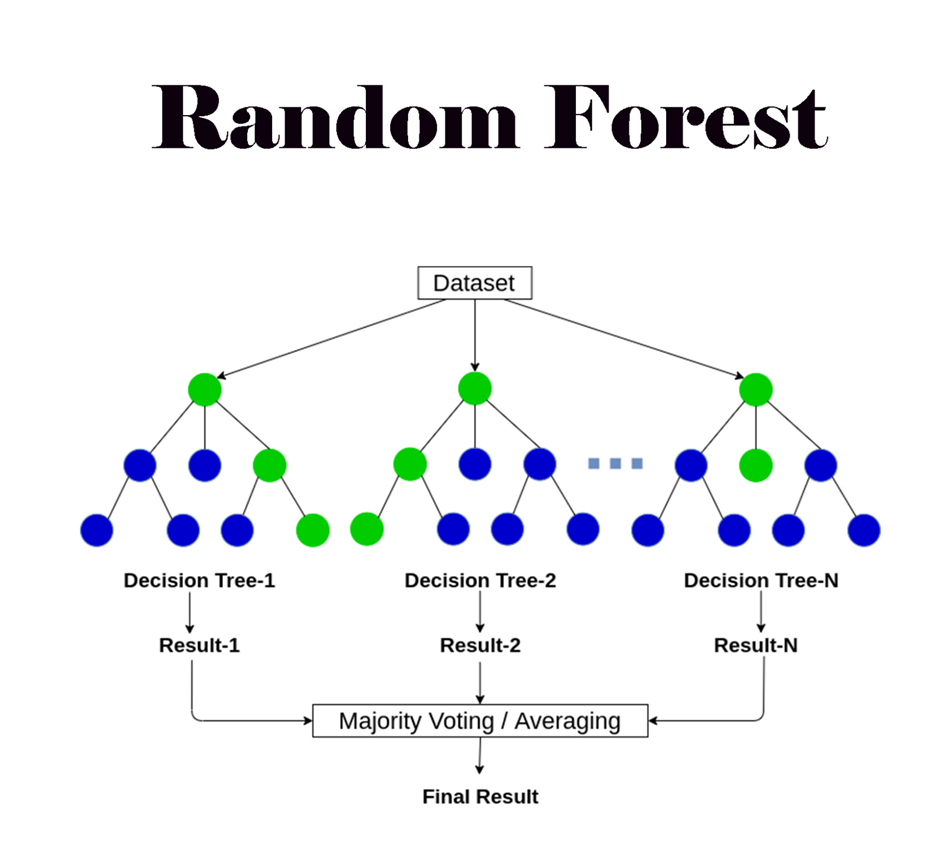
RandomForest는 의사결정 나무에 배깅을 적용하고 변수선택에 랜덤성을 부여한 모델이다.
의사결정 나무의 경우에는 데이터에 과적합 되는 경향이 있는데 RandomForest의 경우 트리 수가 많아도
개별 나무 상관성이 낮기 때문에 전체 분산과 예측 오류를 낮춰주어 과적합 방지가 된다.
비교적 빠른 수행 속도를 가지며 높은 예측 성능을 보이는 것으로 알려져있다.
XGBoost Regressor
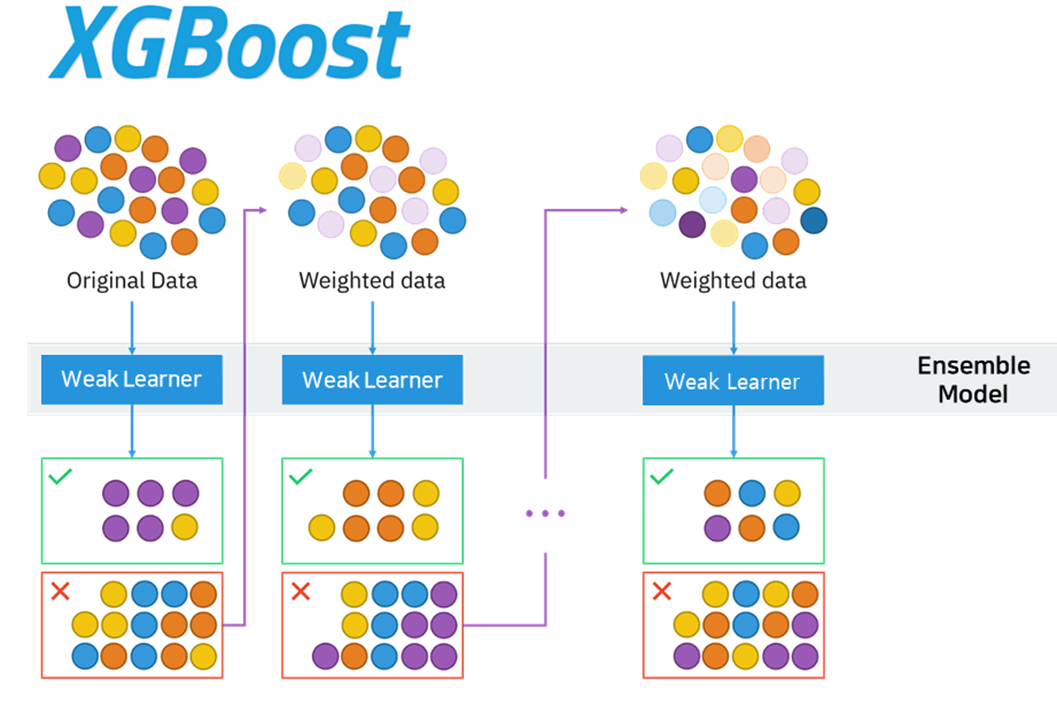
XGBoost는 의사결정나무에 부스팅 기법을 적용한 GBM(Gradient Boosting Machine)을
병렬학습이 가능하도록 발전시킨 모델이다.
약한 학습기를 순차적으로 연결하고 이전 학습기에서 잘못 예측한 데이터에 대해 가중치를 부여하는 방식으로
차후 학습기가 더 잘 예측할 수 있게 개선하는 방식으로 강한 학습기를 만드는 특징을 가진다.
XGBoost는 L1, L2규제 등을 통해 과적합의 문제를 개선할 수 있으며
뛰어난 예측 성능을 가진 것으로 알려져 있다.
본 프로젝트에서는 크게 총 3가지 모델링을 수행하였다.
모델 1
결측치를 보간하지 않고 삭제한 데이터로 학습한 모델
모델2
머신러닝 기법(RandomForest)를 통해 결측치를 보간하여 학습한 모델
모델3
모델2의 결측치 보간 데이터를 world 파생변수 값(New world, Old world)
에 따라 데이터를 두 개로 나누어 각각 학습한 모델

각각의 모델은 모두 RandomForest와 XGBoost의 Regression 모델을 통해 와인 가격을 예측하였고
하이퍼 파라미터 튜닝 자동화 프레임 워크인 Optuna를 이용하여 파라미터를 튜닝하였다.
그리고 모델을 통해 예측한 뒤 모델 성능을 비교하였고 XAI(eXplainable Artificial Intelligence) 라이브러리인
SHAP을 이용해 설명변수의 중요도 및 변수의 영향을 시각화 하였다.
결과 및 한계점
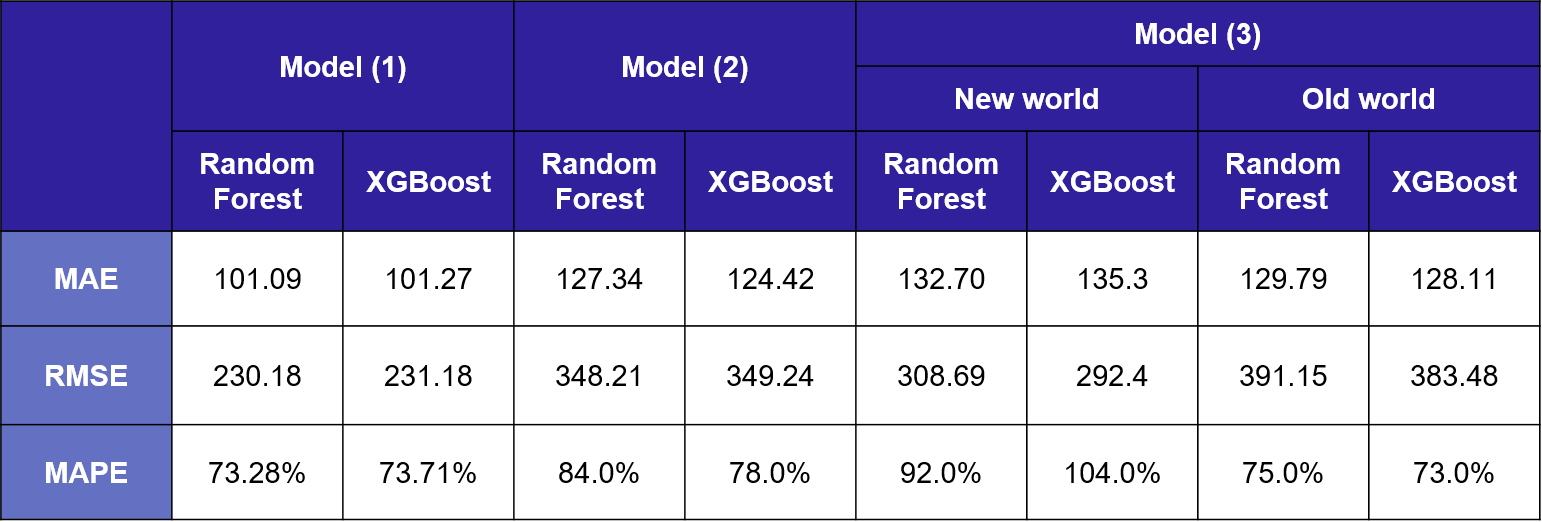
모델 성능지표를 보면 결측치를 단순 삭제 모델(1)이 결측치를 머신러닝 보간한 모델(2)보다도
예측성능이 더 나은 것을 확인할 수 있었다. 머신러닝으로 결측치를 보간하는 것이 성능의 향상을 가져오진 못했다.
New world와 Old world로 데이터를 나눈 모델에서도 MAPE로만 봤을 땐 Old world의 XGBoost 모델에서
예측 성능이 개선된 것으로 보이나 RMSE는 더 높아져 오차가 낮아졌다고 보기는 어려웠다.
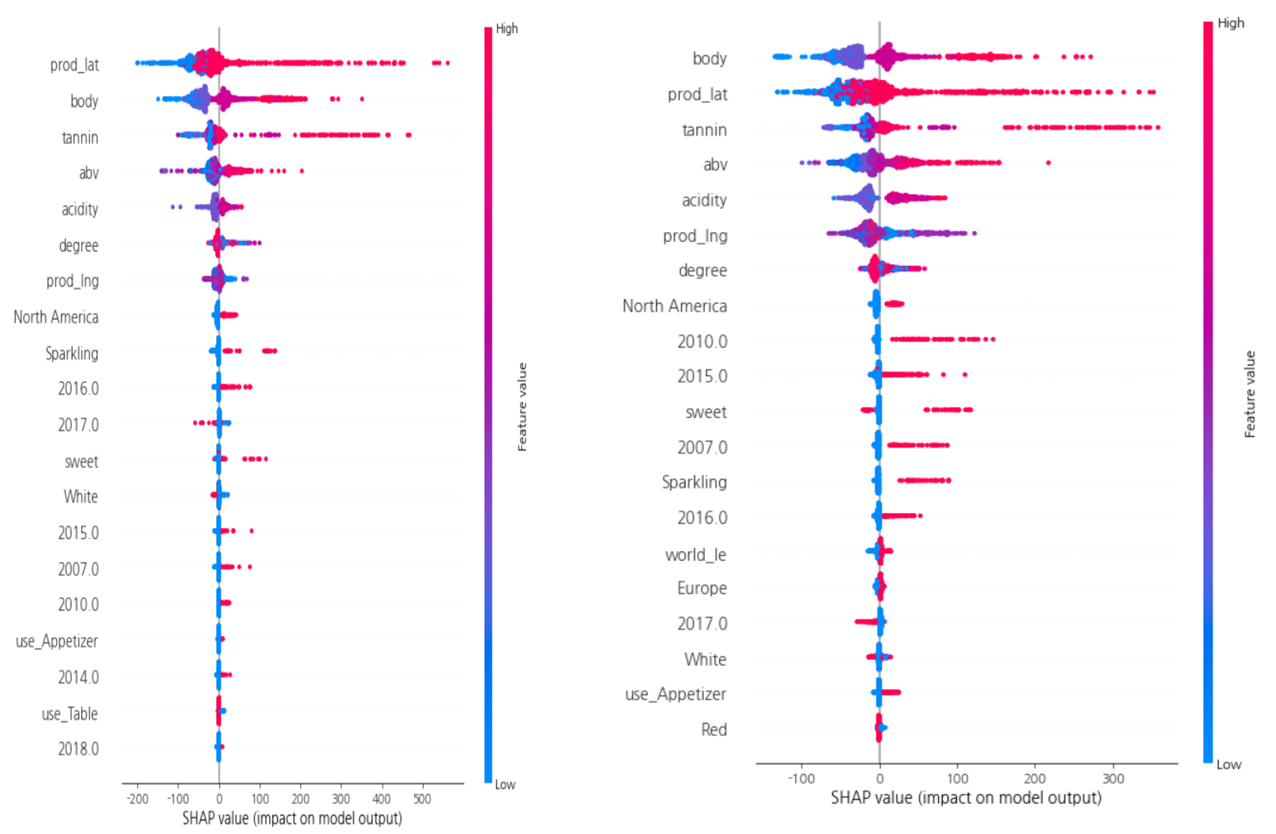
변수 중요도 및 변수의 영향을 보기위한 SHAP 라이브러리의 summary plot 시각화 결과이다.
왼쪽은 RandomForest 모델의 그래프이고 오른쪽은 XGBoost의 그래프인데 두 그래프의 경향은 유사하게 나타났다.
중요도가 높게 나타난 3개의 변수는 prod_lat(위도), body(바디감 점수), tannin(탄닌 점수)으로 나타났다.
각각의 값들은 커질수록 와인가격에 양의 가격을 미치는 것으로 나타났는데
이는 값이 커질수록 와인 값도 비싸지는 것을 의미한다.
위도의 경우에는 와인 평균 가격이 상대적으로 비싼 프랑스, 이탈리아 등의 유럽과 미국이 위도가 다른 곳보다 높아서
나타난 영향으로 보이고
바디감과 탄닌 점수의 경우 값이 높아지면 왜 가격이 높아지는지 그 이유를 바로 알 수는 없었다.
그러다 한 글을 발견했다.
아래의 링크의 글에 따르면 바디감이 높은 "풀바디"와인이 대체로 고가의 가격대이며
바디감에 탄닌이 영향을 미친다고 서술되어 있다.
https://www.wine21.com/11_news/news_view.html?Idx=3227
풀바디 vs 라이트 바디 - 와인21닷컴
와인을 마시다 보면 ‘풀 바디 와인(full-bodied wine)’이라는 말을 자주 듣게 된다. 이는 입안에서 꽉 차는 듯한 묵직한 무게감과 풍부한 맛을 두고 하는 말이다. 와인 초보자들에게는 이러한 느낌
www.wine21.com
따라서 바디감과 탄닌 수치가 높을 수록 와인 가격이 높아졌던 것으로 보인다.
다음은 한계점이다.
이번 프로젝트에 있어서 데이터에서 여러가지 한계점을 느끼게 되었는데
첫 번째, 데이터의 질 및 양의 부족
데이터 칼럼들이 대체로 모델 성능에 도움이 되지 않았다는 점이다.
예측 변수인 Price와 선형성을 갖고 있는 데이터가 거의 없었다. 그리고 데이터 로우 숫자 또한 적어서
전체적으로 모델 예측 성능이 낮게 나올 수 밖에 없었다고 본다.
두 번째, 관련 데이터(추가)의 부족
와인의 가격을 결정하는 요소 자체가 와인 생산량(공급), 수요, 포도밭의 땅값, 포도의 선별 방식, 와인의 관리 방식,
코르크 가격, 병 레이블 가격 상당히 많은 요소가 개입한다는 것을 알 수 있었는데 이를 데이터화 하기 어려워서
관련 데이터를 추가로 붙이는 것이 어려웠다.
세 번째, 한국 와인 가격 데이터이기 때문
사용한 데이터가 한국 사이트에서 수집이 된 와인 데이터라고 기술되어 있었는데, 한국 와인의 경우
수입사의 주문 물량, 생산지에서 운송해오는 방식 등 무역 거래조건에 의해서 가격이 많이 달라지게 된다.
그러나 이러한 부분을 모델에 반영할 데이터가 없었다.
다음은 우리 조에서 생각했던 보완점이다.
위의 이미지는 와인 평가 사이트로 유명한 VIVINO이다.
이 사이트 이외에도 전세계의 와인을 평가하는 사이트가 다수 존재한다.
VIVINO를 예로 들면 와인의 품종, 생산국 뿐만 아니라 이 와인을 평균적으로 얼마에 소비자들이 구매했는지,
와인의 향 관련 노트 등 다양한 정보들을 얻을 수 있다.
이러한 와인 평가 사이트를 크롤링하여서 데이터를 더 많이 수집한다면 한계점에서 설명하였던
데이터의 부족과 한국 가격 데이터가 가지는 문제점을 해결할 수 있을 것이라고 생각하였다.
최종 발표 자료
https://jinhyunbae.tistory.com/158
<TIL> 2024-02-20
오늘 진행한 일 팀 프로젝트 회고 팀 프로젝트 결과 Develop 고민 스파르타 tableu 강의 수강 어제자로 팀프로젝트 발표가 마무리되었고 발표에 대한 피드백을 받았다. 어제는 일정이 있어 TIL을 작
jinhyunbae.tistory.com
https://jinhyunbae.tistory.com/160
<TIL> 2024-02-21
오늘 진행한 일 스파르타 tableu 강의 수강 팀 프로젝트 내용 블로그 작성 팀 프로젝트 Develop, 튜터님께 문의 우선 본격적으로 tableud 강의를 수강하기 시작했다. 확실히 파이썬 코드로 치려면 한참
jinhyunbae.tistory.com
위 TIL 링크에는 과제가 끝난 후 프로젝트에 대한 Develop 시도 과정을 적어놓았다.
결과적으로 모델을 개선 시키는데는 실패하였지만 시도 과정에서 배우는 것들이 많았기 때문에
좋은 시도였다고 생각한다.
'내일배움캠프(데이터 분석 부트캠프 1기) > 팀프로젝트' 카테고리의 다른 글
실전 프로젝트 KPT 회고 (0) 2024.03.13 <심화 프로젝트> 와인 가격 예측 - 1 (0) 2024.02.21 <기초 프로젝트> 고객 분석에 따른 마케팅 전략 제안 -2 (Customer Personality Analysis) (0) 2024.01.19 <기초 프로젝트> 고객 분석에 따른 마케팅 전략 제안 -1 (Customer Personality Analysis) (0) 2024.01.19