-
데이터 리터러시(Data Literacy) -2데이터 분석 관련 공부 2024. 1. 3. 19:52
본 블로그는 스파르타의 데이터 리터러시 강의를 듣고 간략하게 정리한 것이다.)
<이전 글 : 데이터 리터러시(Data Literacy)-1 https://jinhyunbae.tistory.com/97 >
데이터 리터러시(Data Literacy) -1
(본 블로그는 스파르타의 데이터 리터러시 강의를 듣고 간략하게 정리한 것이다.) 데이터 리터러시(Data Literacy) 데이터 리터러시의 정의 데이터를 읽는 능력 데이터를 이해하는 능력 데이터를 비
jinhyunbae.tistory.com
데이터 유형
정량적 데이터
- 수치로 표현되는 정보로 양적인 측정과 분석을 통해 얻을 수 있음
- 데이터가 숫자 형태로 존재하기 때문에 통계 분석이 용이함
- 개인의 해석이나 주관이 적게 작용하는 객관성을 가짐
- 지표로 만들기 용이함
- 수치형 설문조사, 인구 통계, 비즈니스 데이터, 마케팅 데이터, 로그 데이터 등이 있음
정성적 데이터
- 비수치적 정보로 사람의 경험이나 관점, 태도와 같은 주관적 요소를 포함함
- 텍스트, 비디오, 오디오의 형태로 대부분 존재함
- 정형화 되어 있지 않아서 구조화시키기가 어려움
- 새로운 현상이나 개념에 대한 이해를 심화하는데 많이 사용함
- 이미지 처리, 음성 분석, 자연어 처리 등의 기술을 이용해 분석 가능한 데이터로 활용하기도 함
지표 설정
지표의 정의
- 특정한 목표나 성과를 측정하기 위한 구체적이고 측정 가능한 기준
- 목표 달성도를 평가하고 전략적 결정에 필요한 핵심 정보를 제공함
- 정의한 문제에 대해서 정확하게 파악하기 위해서 필요함
문제 정의가 어떤 문제를 풀고자 하는가를 정의하는 것이라면 지표는 어떠한 결과를 기대하는가에 대한 정량화된 기준
문제 정의에서와 마찬가지로 구체적이고 명확한 기준을 제시해야한다.
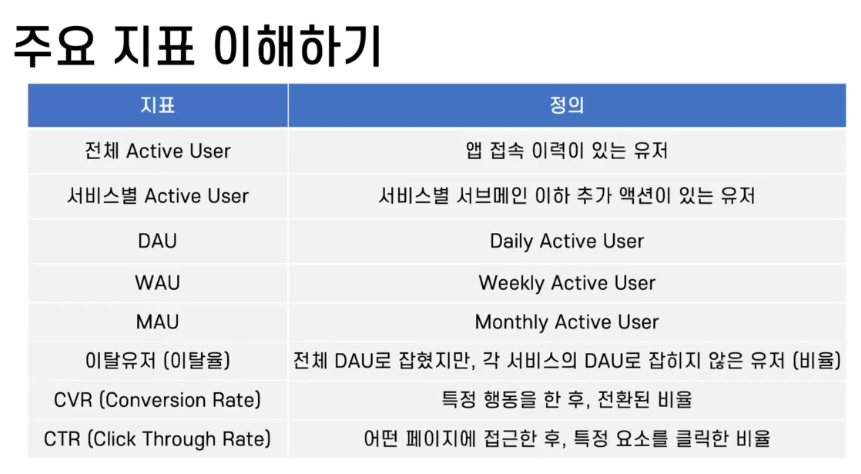
출처 : 스파르타 데이터 리터러시 강의자료
Active User(활성 유저)
특정 기간동안 앱과 상호작용한 사용자
활성 유저의 정의에 따라서 전략과 방향이 달라지고, 해당 정의에 따라 이탈 유저가 정의된다.
활성 유저는 서비스 지표에 중요한 역할을 한다.
<설정 사례 (학습 플랫폼 운영)>
1) 사이트 진입 유저
- 메인 홈 화면에 진입한 유저를 활성 유저로 정의한다고 했을 때
- 허들이 가장 낮아 활성 유저 지표가 가장 높게 측정됨
- 그러나 해당 유저 대상의 액션 효율이 떨어질 것임
2) 사이트 진입 후 추가 행동을 한 유저
- 사이트에 진입하여 강의 중 하나에 진입한 유저로 활성 유저를 정의
- 허들이 사이트 진입보단 높음
- 1)번 보다는 대상 액션 효율이 높음
3) 서비스의 최종 액션(목표 액션)까지 수행한 유저
- 자사 서비스의 Goal 액션(예를들어 강의 수강 완료)을 한 유저
- 자사 서비스의 핵심과 효용성을 이미 경험한 유저
- 가장 허들이 높은 활성유저임
- 해당 유저 대상으로 액션을 하면 효율과 이익이 가장 높음
- 그러나 활성유저 지표는 가장 낮게 측정될 것임
서비스에 따라 그에 맞는 활성 유저를 설정하는 것이 필요하다.
- 어디까지 경험한 유저를 활성 유저로 볼 것인가
- 일반 유저와 활성 유저를 나누는 기준은 어떻게 할 것인가
- 유저는 어디서 우리의 서비스 효용성을 느끼는가
- 우리가 핸들링할 수 있는 유저의 사이즈는 얼마나 되는가
Retention Ratio(재방문율)
몇 %의 유저가 우리 서비스를 다시 사용하는가?
- 정의 : 서비스를 사용한 사람이 다시 서비스를 사용하는 비율
- 리텐션이란 한번 획득한 유저가 서비스로 다시 돌아왔는가에 대한 지표로
- 리텐션이 높은 서비스는 유저 획득에 투자한 비용(마케팅 비용 등)을 빠르게 회수할 수 있다.
- 리텐션은 특히 앱서비스의 성장에서 매우 중요한 지표
<Retention 측정 방법>
1) N-day 리텐션

출처 : 스파르타 데이터 리터러시 강의 자료 - 최초 사용일로부터 N일 후 재방문한 활성 유저 비율
- 일반적으로 N-day리텐션 지표를 많이 사용함
- 게임, SNS, 메신저 등 매일의 반복적인 행동을 유도하는 서비스 혹은 제품에 적합함
- 유저가 활성 유저로 집계된 최초의 날을 Day-0으로 설정
- Day0에 Active 상태가 된 모든 유저의 N일차 리텐션을 계산함
- N-Week, N-Month 계산도 가능함
- 서비스 사용 주기가 길 경우에는 N-day 리텐션을 사용하면 실제보다도 더 과소평가 될 수 있다.
2) Unbounded 리텐션

출처 : 스파르타 데이터 리터러시 강의 자료 - 특정한 날짜를 포함하여 그 이후에 재방문한 유저의 비율
- 특정일을 포함하여 그 이후에 한번이라도 재방문하게 되면 그 전까지 집계함
- 유저가 비정기적으로 방문하는 서비스에 적합함(채용 사이트, 쇼핑몰, 부동산 매물 서비스)
- Unbounded 리텐션은 이탈율의 반대 개념에 해당함
- N-day 리텐션과 비교하면 큰 차이를 보임
- 접속하지 않던 유저가 접속하는 경우 그 이전 리텐션 값들이 전부 변동되는 상황이 발생할 수 있음
- 절대적인 지표로 활용하기 보단 어떻게 변화하는지 트렌트를 보는 용도로 활용하면 좋음
3) Braket 리텐션
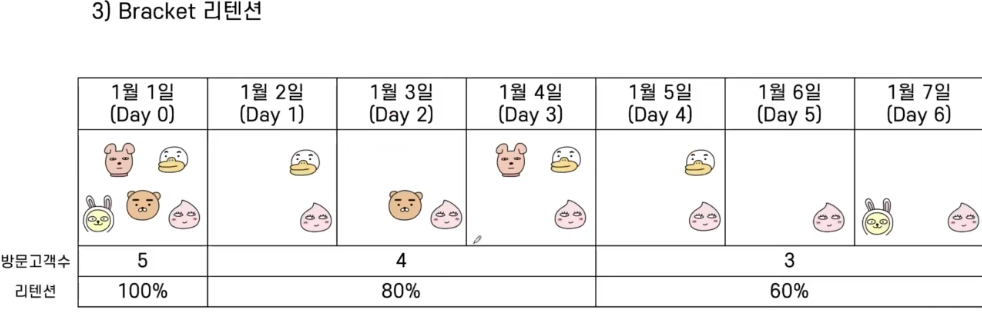
출처 : 스파르타 데이터 리터러시 강의 자료 - 설정한 특정 기간을 기반으로 재방문율을 측정함
- Braket 리텐션은 N-Day리텐션을 확장한 개념으로 일/주/월 단위가 아닌 지정한 구간으로 나눔
- 활성 유저가 특정한 활동을 위해 각 Braket 내에 서비스에 재방문시 잔존 유저로 해석함
- Braket 안에만 접속하면 리텐션에 영향을 주지 않기 때문에 기준이 널럴하다고 할 수 있음
- 서비스 사용주기가 길거나 주기적인 경우 사용하기에 적합한 지표(식료품 배달 서비스 등)
리텐션이 높은 세그먼트를 발굴하는 작업이 필요하고 해당 세그먼트에 필요한 액션을 생각해보거나
리텐션이 낮은 세그먼트를 높은 세그먼트가 되도록 유도할 수 있는 지 생각해볼 수 있다.
서비스의 사용 주기에 따라 리텐션을 조회하는 기간을 설정해야한다.
리텐션의 경우 후행지표(*)로 사후 분석에 매우 용이한 지표이다.
* 선행지표 : 행동 및 컨트롤이 가능한 지표로 후행지표 생성과 인과관계가 있는 지표이다. / 측정이 가능한 것이어야한다. (ex 전환율)
* 후행지표 : 비즈니스 성과를 측정하는 지표로 선행지표의 달성으로 인해 나오는 결과 값이다. (ex 매출, 리텐션)
Funnel(퍼널)
AARRR
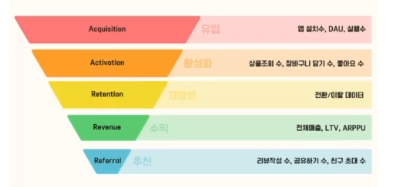
출처 : 스파르타 데이터 리터러시 강의 자료 - 디지털 마케팅시 활용하는 프레임워크
- 단계별 전환율을 지표화해서 서비스 보완지점을 찾는 용도로 사용됨
- Acquisition : 유입
- Activation : 활성화
- Retention : 재방문(재구매)
- Revenue : 수익
- Referral : 추천
LTV(Life Time Value, 고객 평생 가치)
한 유저가 생애주기 동안 가져다주는 이익을 정량화한 지표이다. CLV 혹은 CLTV라고도 한다.
- LTV는 유저와의 관계를 측정하고 이를 사업적 이익으로 가져가는데 중요한 지표
- LTV가 높다는 것은 해당 서비스와의 관계가 좋고, 충성도가 높은 고객이 많다는 것
- LTV 추측이 가능하다면 신규 유저 유입 비용(CAC:Customer Acquisition Cost)의 산출 및 효율적 예산 운용이 가능함
LTV 산출 방법
- 이익 * LifeTime * 할인율(미래 비용에 대한 현재 가치)
- 연간 거래액 * 수익률 * 고객 지속 연수
- 고객의 평균 구매 단가 * 평균 구매 횟수
- (매출액 - 매출 원가) / 구매자 수
- 평균 구매 단가 * 구매 빈도 * 구매 기간
- (평균 구매 단가 * 구매 빈도 * 구매기간) - (신규 획득 비용 + 고객 유지 비용)
- 월 평균 객단가 / 월 잔존율
LTV 산출 방법은 매우 다양하며 정답이 없다. - 서비스에 따라 다르게 적용해야한다.
- 자사 서비스에 맞는 LTV를 산출하는 것은 매우 어려운 일이다.
- 사용 주기 변수 객단가 등 여러가지를 고려해야한다.
- LTV는 가정을 베이스로 하는 지표이기 때문에 꾸준한 모니터링이 필요하다.
https://jinhyunbae.tistory.com/94 에서 고객평생가치에 대해서 정리하였던 적이 있다(참고)
북극성 지표
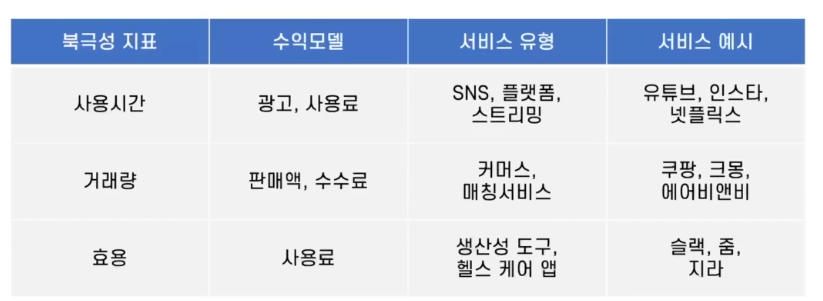
출처 : 스파르타 데이터 리터러시 강의 자료 제품 / 서비스의 전략의 핵심으로 '성공'을 정의하는 지표
- 제품/서비스가 유저에게 주는 Core Value를 가장 잘 나타낸 지표
- 유저가 제품/서비스에서 느끼는 가치(만족도)에 해당함
- 회사 사업의 목표를 나타내는 지표 중 선행지표(후행지표 X)
- 장기 성장을 위해 필수적으로 모니터링 해야함
좋은 북극성 지표를 위한 체크리스트
- 유저가 목적을 달성하는 때는 언제인가
- 모든 유저에게 해당되는 지표인가
- 측정 가능한 지표인가
- 측정하는 주기는 적절한가(일, 주, 월...)
- 외부요인으로 부터 영향을 많이 받지는 않는가
- 북극성 지표의 성장이 사업의 성장과 함께하는가
- AARRR 퍼널의 전과정이 북극성 지표에 영향을 주는가
- 북극성 지표의 변화를 적어도 매주 관찰 가능한가
북극성 지표는 무엇에 집중해야하고 무엇을 포기해도 되는가에 대한 방향을 제시한다.
또한 제품/서비스의 진척과 가치창출을 전사에 보여주어 직원들을 하나에 목표에 집중시켜 서로 상반된 목표에 집중하거나 중복으로 일하는 것을 방지한다(MECE한 구조) 그리고 이에 따라 액션의 실행 속도가 빨라진다.
그리고 제품/서비스 조직이 결과에 책임을 지도록 한다.
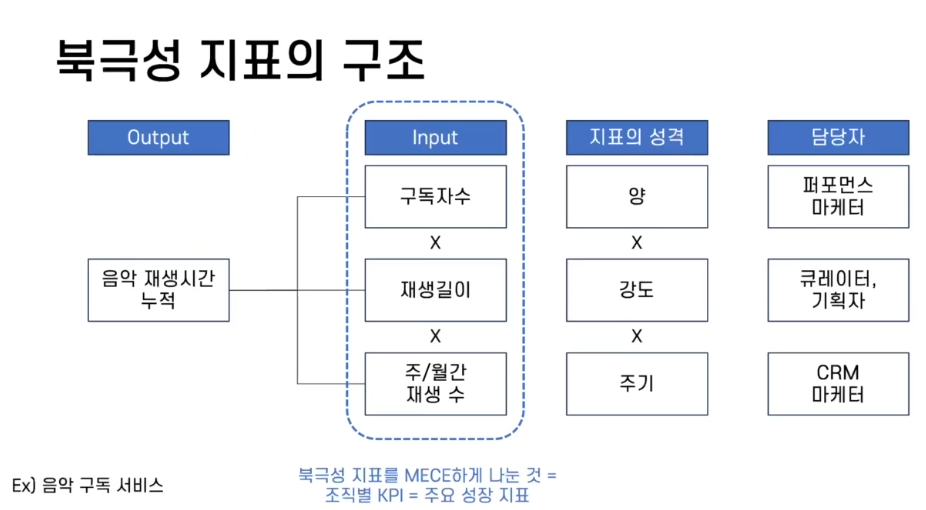
출처 : 스파르타 데이터 리터러시 강의 자료
결론 도출
결과와 결론을 구분할 필요성이 있다.
결과
- 데이터 처리, 분석, 모델링 후 얻어진 구체적인 데이터의 출력
- 숫자, 통계, 그래프, 차트의 형태로 나타남
결론
- 분석된 데이터 결과를 바탕으로 이끌어낸 의미나 통찰
- 데이터에 기반한 해석, 추론 또는 권고사항을 포함함
결과는 계산과 분석을 해서 나온 결과물이고 결론은 묵적에 대해 어떠한 의미가 있는지를 설명하는 것이다.
결과를 결론으로 오인하는 실수를 조심해야한다.
결과를 통해 결론을 도출하는 것에는 스토리텔링이 필요한데 이 때
필요 이상으로 자신의 해석을 융합해선 안되며 데이터를 통해 알 수 있는 범위 내에서 생각해야한다.
- 문제 정의, 지표 설정을 할 당시의 목적을 떠올리며 결론을 정리해야한다.
- 또한 결론을 공유할 대상이 누구인지, 결론을 통해 어떻게 변화하기를 원하는지를 고민해야한다.
- 핵심 지표를 위주로 해석하고 액션 아이템을 제안하는 것이 중요하며
- 모든 내용을 담지 말고 결론을 듣는 당사자(경영진)이 궁금해할만한 내용 위주로 제공하는 것이 맞다.
- 이 때 대상자의 시선에서 이해하기 쉽도록 정리해야한다.

결론 보고서 플로우 <출처 : 스파르타 데이터 리터러시 강의자료>
결국 데이터 리터러시란?
- 눈 앞에 있는 데이터에 의존하지 않고 스스로 목적과 문제를 정의
- 목적을 달성하는 데 필요한 데이터와 지표를 설정하는 것
- 데이터를 어떻게 봐야 문제 정보를 효과적으로 얻을 수 있는지 분석하는 것
- 데이터를 보는 방식이나 방법론, 통계지식에 매몰되지 않고 항상 '왜?' 를 생각하는 것
- 강의를 들으며 느낀 점
스파르타에서 들었던 그 어떤 강의보다도 도움이 되는 강의가 아니었나 싶다.
대학원에서 처음 데이터를 분석할 때 새롭게 배우는 방법론이나 통계지식에 자주 매몰되었던 것 같은데
다시 한 번 내가 분석했던 내용들을 돌아볼 수 있게 만들어 주는 강의였고
이 강의의 내용이 앞으로 DA로 거듭나기 위해 가장 머리에 새겨야할 내용이라고 생각했다.
'데이터 분석 관련 공부' 카테고리의 다른 글
<통계학> 통계적 가설 검정 -1 (귀무가설, 대립가설, p-value) (1) 2024.01.22 <통계학> 큰 수의 법칙, 중심극한정리 (1) 2024.01.22 <Python, SQL> pymysql 라이브러리(with Pandas DataFrame) (0) 2024.01.12 <SQL : MySQL> RECURSIVE(재귀 쿼리) (0) 2024.01.09 데이터 리터러시(Data Literacy) -1 (1) 2024.01.03