-
<TIL> 2024-03-14내일배움캠프(데이터 분석 부트캠프 1기)/TIL & WIL 2024. 3. 14. 23:47
- 오늘 진행한 일
- 학습 주차 팀빌딩
- Spark 강의 수강
그저께 까지는 실전 프로젝트 조와 프로젝트를 진행하였고
어제는 인터넷 관련 문제를 해결하고 국민 취업 지원제도 관련 상담도 받고
팀 프로젝트 회고를 진행하는 등 정신없는 하루들을 보냈다.
그래서 신청했던 F&B 태블로 신병 훈련소 과정이 4일차에 접어들었는데도
아직 한 문제도 풀어보질 못하였다.
그래도 과제 제출은 3월 20일까지니까 주말까지 활용하여 과제를 제출하고자한다.
F&B를 위한 태블로 신병훈련소 2024.03
F&B를 위한 태블로 신병훈련소 2024.03
www.salesforce.com
오늘은 최종 프로젝트 전에 진행될 학습 주차에서의 조 편성이 있었다.
팀프로젝트를 함께하는 조는 아니기 때문에 간단한 자기소개를 나누는 시간을 가지고
오후 조금 늦게 학습을 시작하였다.
Spark를 이용한 빅데이터 분석이라는 강의였는데
첫 강의주차는 어째서 스파크를 다루는 지에 대해서 배웠다.
이름만 들어봤지 실제로 다뤄본 적은 없었는데 강의의 전반은 사실
스파크를 다룬다기 보단 대용량 데이터를 다루는 데 있어서 알아야할 지식에 관한 강의였다.
데이터 타입에 따라 메모리에 차지하는 용량의 차이에 대해서 배우고,
데이터가 저장되는 파일 유형에 따라서 시, 공간적인 비용의 차이가 있는지를 배웠다.
데이터 타입
적절한 데이터 타입을 사용하면 30% 이상의 메모리를 절약할 수 있는데 이는 판다스 데이터 프레임에서
기본적으로 넉넉하게 메모리를 할당하기 때문이다.
정수형(Integer)

Integer 컴퓨터에서는 정수는 이진법으로 표현하기 때문에 더 많은 비트를 할당하면 더 큰 숫자를 담을 수 있다.
판다스에서는 정수형 데이터에서는 int64를 기본으로 할당하기 때문에 실제로 필요한 정수의 크기가
그만큼의 크기를 넘지 않는다면 int32, int8로 자료의 크기를 줄이기만해도 상당히 많은 시공간적 이익을 얻을 수 있다.
실수형(Float)

부동소수점(Float) 컴퓨터에서 정수가 아닌 데이터를 표현하기 위해서 사용하는 방법이 부동 소수점이다.
부동 소수점은 하나의 숫자를 형태와 자릿수로 구분하여 표현하는 것이다.
부동소수점 또한 정수와 마찬가지로 float16, float64 등을 사용하는데, 더 큰 메모리를 사용할수록
값이 정확해지지만 데이터가 더 무거워집니다.
부동 소수점에 대한 자세한 내용은 아래 링크를 참고하였다.
부동소수점에 대해 알아보자
개념은 확실히 잡아야지🔥 / 진행 중
velog.io
String, Category(Object)

String 데이터 표현 문자열은 수치형 데이터보다 더 복잡한데 일반적으로 대부분 소프트웨어는
유니코드를 이용해 문자열을 인코딩한다고 한다.
위 정수형이나 실수형 데이터보다도 훨씬 많은 용량을 차지하기 때문에 이에 대한 대안으로
범주형 자료를 사용하는 방법을 생각해볼 수 있다. 본래 문자열로 이루어졌던 데이터를 범주형으로 하여
각 데이터 고유값을 내부에서 숫자로 치환하여 사용하는 것으로 상당히 많은 양의
메모리를 절약할 수 있게 되는 것이다.
Parquet(파케이)

데이터를 디스크에 저장할 때 가장 효율적이라고 알려져있는 파일의 포맷이 바로 파케이이다.
csv를 가장 흔하게 사용하는 포맷으로 나도 항상 csv를 사용하고는 했는데
가장 느리고 가장 무겁다는 것을 알게 되었다. 파일을 읽는데 걸리는 시간과 저장된 파일의 크기 및 입출력 시에
필요한 메모리의 관점에서는 csv는 굉장히 별로일 수 있겠다는 생각이 들었다.
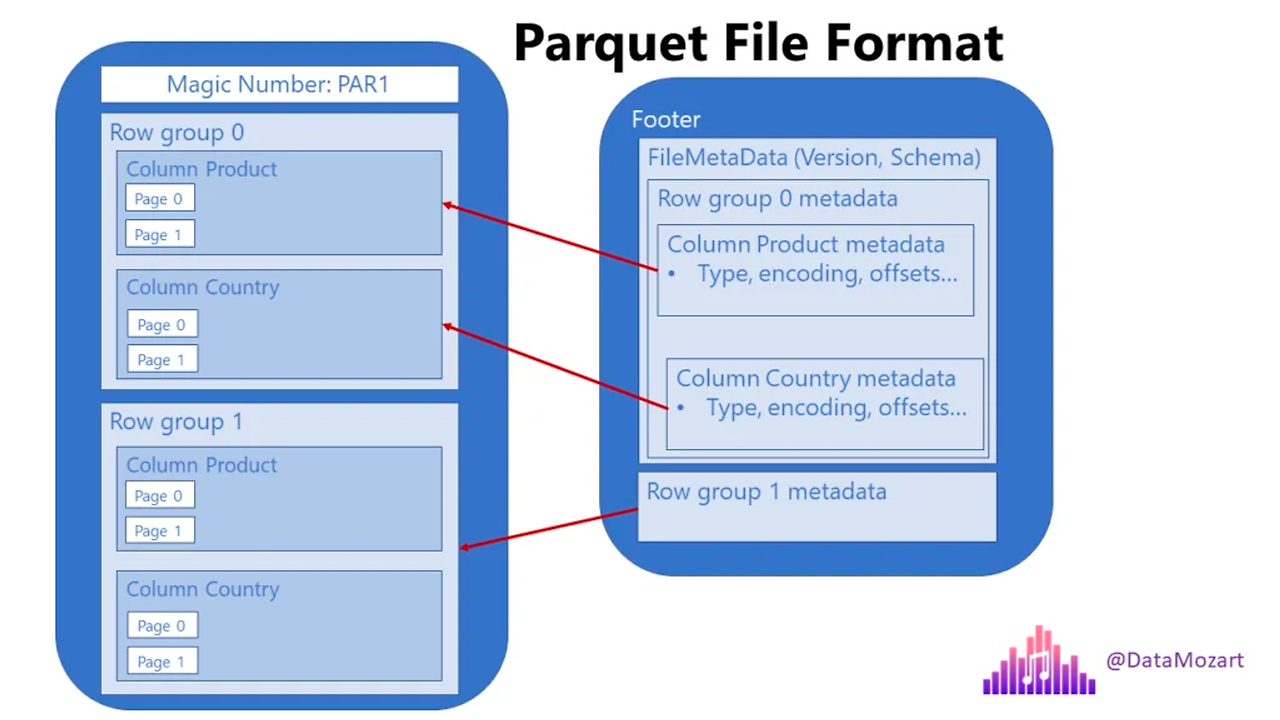
파케이는 대용량 데이터 저장에서의 표준이며 굉장히 가볍고 빠른 것으로 알려져있다고 한다.
다수의 OLAB 데이터베이스가 내부적으로 파케이를 사용하여 데이터를 저장하고 있다.
그리고 Spark또한 파케이를 지원한다. 강의를 진행한 튜터분도 그렇고 데이터 분석 오픈 카톡방에서
현직자분도 거의 대용량 데이터를 다뤄야하면 무조건 파케이를 다루신다고 하셨다.
직접 2기가바이트 정도의 데이터를 다뤄보니 파케이로 불러올 때는 내 컴퓨터에서 20초 정도 걸리는 데이터를
csv로 불러오려고 하니 컴퓨터가 거의 멈출 정도로 메모리를 잡아먹고 시간 또한 어마어마하게 오래걸리는 것을
확인할 수 있었다.
지난 번 프로젝트에서도 그랬지만 메모리 관점에서 조금 더 효율적인 코드를 활용하고 자료형을 선택하는 것이
시간적인 부분에서도 상당히 중요하다는 생각이 들었다.
내일은 스파크 강의를 마저 듣고 정리해보려고 하고
주말에는 태블로 신병캠프의 문제를 차근차근 풀어보려고한다.
'내일배움캠프(데이터 분석 부트캠프 1기) > TIL & WIL' 카테고리의 다른 글
<WIL> 2024년 3월 둘째 주 회고 (1) 2024.03.15 <TIL> 2024-03-15 (1) 2024.03.15 <WIL> 2024년 3월 첫째 주 회고 (1) 2024.03.08 <TIL> 2024-03-08 (0) 2024.03.08 <TIL> 2024-03-05 (2) 2024.03.05 - 오늘 진행한 일