-
<머신러닝> 개인 과제(with XGBoost)내일배움캠프(데이터 분석 부트캠프 1기)/개인과제 2024. 2. 6. 00:36
머신러닝 개인과제는
금융 데이터로 텔레마케팅 권유를 하기 위해
대출을 할 것 같은 고객을 사전에 선별하는 분류 알고리즘을 짜는 것이었다.
필수 문제는 사전에 제공되는 Jupyter notebook에 빈칸 채워넣기 문제였다.
해당 문제는 빠르게 답안을 작성하여 제출하였고
심화학습을 위해서 사전에 제공된 notebook 없이 데이터 불러오는 단계에서부터
EDA, 전처리, 모델학습 및 평가를 수행하는 실습을 진행했다.
사용한 데이터는 UCI 데이터 저장소의 Bank Marketing 데이터였다.
https://archive.ics.uci.edu/dataset/222/bank+marketing
UCI Machine Learning Repository
Input variables: # bank client data: 1 - age (numeric) 2 - job : type of job (categorical: "admin.","unknown","unemployed","management","housemaid","entrepreneur","student", "blue-collar","self-employed","retired","technician","services") 3 - marital : mar
archive.ics.uci.edu
데이터 불러오기
사용한 라이브러리를 불러오는 코드이다.
import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import ucimlrepo from sklearn.experimental import enable_iterative_imputer from sklearn.impute import IterativeImputer from sklearn.model_selection import train_test_split from imblearn.over_sampling import SMOTE from sklearn.preprocessing import LabelEncoder from sklearn.preprocessing import StandardScaler, MinMaxScaler import optuna from optuna.samplers import TPESampler from optuna import Trial from xgboost import XGBClassifier from sklearn.metrics import accuracy_score, f1_score import warnings warnings.filterwarnings('ignore')ucimlrepo 라이브러리를 통해 Bank Marketing 데이터를 요청 받아오고
이를 DataFrame으로 하여 로컬환경에 저장한 뒤 불러와서 사용하였다.
bm = ucimlrepo.fetch_ucirepo(name='Bank Marketing') features = bm.data.features targets = bm.data.targets bank_marketing = pd.concat([features, targets], axis=1) bank_marketing.to_csv('./data/bank_marketing.csv', index=False) bank_marketing = pd.read_csv('./data/bank_marketing.csv')EDA
bank_marketing.info()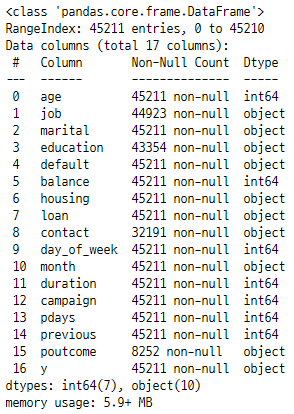
info()로 확인한 결과 결측치가 있는 것을 확인할 수 있고 변수의 자료형을 확인할 수 있다.
bank_marketing.isnull().sum()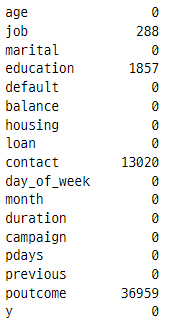
결측치가 얼마나 있는 지 확실하게 본 결과 범주형 변수 데이터에 결측치가 상당수 존재하는걸 확인할 수 있다.
결측치를 어떻게 할 지 고민하는게 이번 개인과제에서의 가장 큰 부분을 차지했다.
bank_marketing.describe(include='all')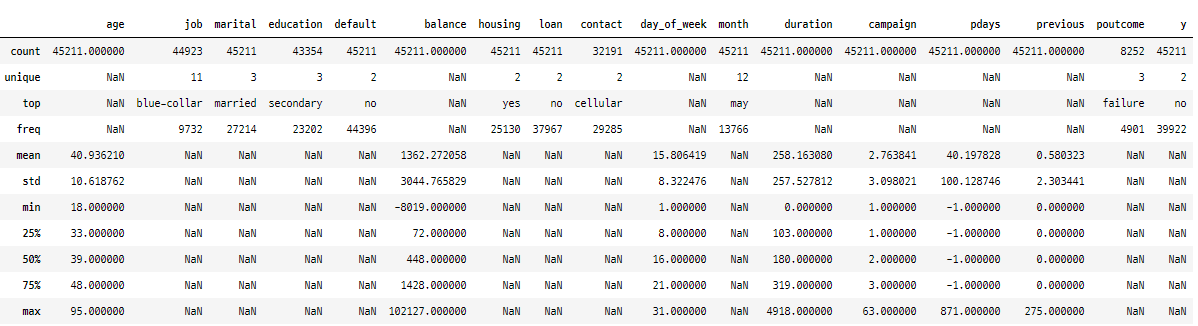
bank_marketing[['balance']].loc[bank_marketing['balance'] < 0]
그리고 balance(예금)이 음수인 데이터가 3,766개 존재했는데 전체 데이터가 4만 5천개인 것을 고려하면 꽤 row수가 있는 편이다. 그리고 음수 데이터가 다양하게 분포하고 있어, 빚이라거나 마이너스 통장 같은게 아닐까 싶었다.
이상치로 간주해서 삭제하거나 0으로 밀어버리는 것보다는 이를 보정을 해주는게 낫겠다고 생각했다.
plt.figure(figsize=(15, 5 * (len(numeric_col) // 3))) for i, col in enumerate(numeric_col): plt.subplot(len(numeric_col) // 3 + (len(numeric_col) % 3 > 0), 3, i + 1) sns.histplot(bank_marketing[col]) plt.title(col) plt.tight_layout() plt.show()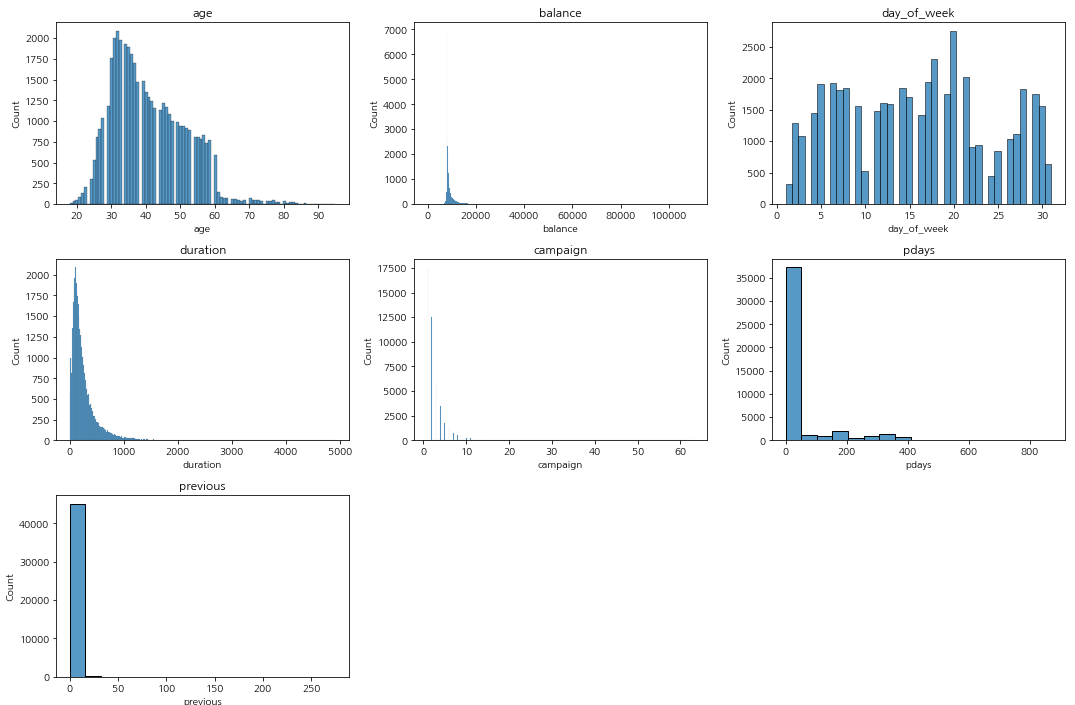
수치형 데이터를 보면 우측 편포가 심한 데이터가 있는 것을 확인할 수 있다.
bm_df['y'].value_counts().to_frame()
그리고 타겟 변수인 y의 값이 상당히 불균형하다는 것을 확인할 수 있었다. 대출을 받고 안받고이니 당연히 이러한 분포가 나타나는 것이 맞지만 머신러닝 학습을 위해서 데이터 불균형 문제는 해결해줄 필요가 있었다.
전처리
우선 전처리 해야할 것은
balance의 음수 데이터, 데이터 편포, 결측치, 범주형 변수의 인코딩, 데이터 불균형이 있었다.
balance_min = abs(min(bank_marketing['balance'])) bank_marketing['balance'] = bank_marketing['balance'] + balance_min먼저 balance의 음수 데이터의 경우에는 이후에 작성할 로그 스케일링을 위해서
최솟값(-8019)의 절댓값을 전체 데이터에 더해주었다.
bm_df = bank_marketing.copy() # 로그스케일 적용 for col in ['duration','balance','previous','campaign']: bm_df[col] = np.log1p(bm_df[col]) plt.figure(figsize=(15, 5 * (len(numeric_col) // 3))) for i, col in enumerate(numeric_col): plt.subplot(len(numeric_col) // 3 + (len(numeric_col) % 3 > 0), 3, i + 1) sns.histplot(bm_df[col]) plt.title(col) plt.tight_layout() plt.show()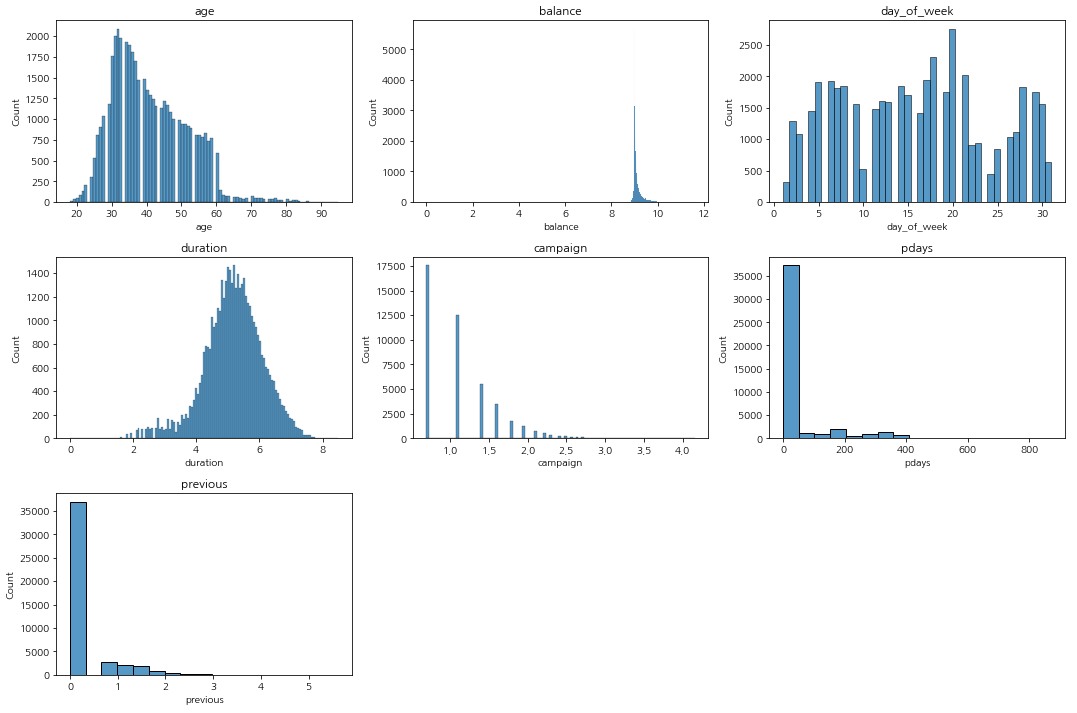
그리고 편포가 심한 데이터들을 로그 스케일링 해주었고 다시 그래프를 그려보았다. duration의 경우에는 종모양으로 예쁘게 분포하게 된 것을 확인할 수 있고 나머지 데이터의 경우에도 조금 완화된 것을 확인할 수 있다.
사실 사용한 모델이 트리 기반 모델이라서 별도로 스케일링을 해줄 필요는 없었지만 한 가지 모델만 적용하는 것이 아니라 비교를 할 수도 있기 때문에 스케일링을 해주었다. 이후 기술할 표준화와 정규화도 마찬가지이다.
def get_binary(x): if x=='no' : return 0 else : return 1 for i in ['default', 'housing', 'loan', 'y'] : bm_df[i] = bm_df[i].apply(get_binary) bm_df
이진 데이터의 경우 yes와 no로 이루어져 있었기 때문에 함수를 apply하는 것으로 한 번에 1, 0으로 레이블 인코딩 해주었다.
job_encoder = LabelEncoder() bm_df['job'].loc[~(bm_df['job'].isnull())] = job_encoder.fit_transform(bm_df['job'].loc[~(bm_df['job'].isnull())]) marital_encoder = LabelEncoder() bm_df['marital'] = marital_encoder.fit_transform(bm_df['marital']) education_encoder = LabelEncoder() bm_df['education'].loc[~(bm_df['education'].isnull())] = education_encoder.fit_transform(bm_df['education'].loc[~(bm_df['education'].isnull())]) contact_encoder = LabelEncoder() bm_df['contact'].loc[~(bm_df['contact'].isnull())] = job_encoder.fit_transform(bm_df['contact'].loc[~(bm_df['contact'].isnull())]) month_encoder = LabelEncoder() bm_df['month'] = marital_encoder.fit_transform(bm_df['month'])그리고 범주의 개수가 3개이상인 변수에 대해서는 레이블 인코딩을 수행했다. 원 핫 인코딩이 아닌 레이블 인코딩을 수행한 이유는 첫 번째로 차원의 개수가 많아지는 것이 모델 성능에 안좋은 영향을 미칠 수 있다고 생각했기 때문이고
트리 기반 모델의 경우에는 값의 크기가 모델 성능에 영향을 주지 않기 때문에 레이블인코딩으로 처리해도 상관이 없기 때문이다.
그리고 데이터 보간을 해야하는데 레이블인코딩 시 NaN값도 하나의 범주로 간주하여 레이블을 부여하게 되기 때문에
결측치 부분은 빼고 인코딩을 하도록 코드를 작성하였다.
imputer_mice = IterativeImputer(random_state=42) bm_df = pd.DataFrame(imputer_mice.fit_transform(bm_df), columns = bm_df.columns) bm_df[['job', 'education', 'contact']] = bm_df[['job', 'education', 'contact']].round().astype(int) bm_df결측치 보간을 위해서 MICE(Multivariate Imputation by Chained Equation) 방법을 사용하였는데 sklearn의 IterativeImputer를 통해서 구현이 가능하다. 레이블 인코딩으로 수치형 변수화를 했기 때문에 해당 방법을 적용할 수 있었고 보간한 데이터를 반올림하여 정수형 데이터 형태로 바꾸어주었다.
https://www.numpyninja.com/post/mice-algorithm-to-impute-missing-values-in-a-dataset
MICE algorithm to Impute missing values in a dataset
Missing data is a common problem in math modeling and machine learning. Machine Learning models cannot inherently work with missing data, and hence it becomes imperative to learn how to properly decide between different kinds of imputation techniques to ac
www.numpyninja.com
MICE의 원리에 대해서 설명한 링크를 첨부한다.
bm_df = bm_df.drop('poutcome', axis=1)그리고 결측치 중에서 poutcome의 경우에는 전체 데이터의 75%의 정도가 결측치였기 때문에 사용 불가능하다고 판단하여 삭제해주었다.
X = bm_df.drop(columns = ['y']) y = bm_df[['y']] X_train, X_test, y_train, y_test = train_test_split(X, y, stratify = y, test_size=0.2, random_state= 42) print(X_train.shape, X_test.shape) print(y_train.shape, y_test.shape)먼저 train_test_split을 통해 test데이터를 분할 하는데 stratify 옵션을 통해 층화 추출을 했다.
mm_sc = MinMaxScaler() sd_sc = StandardScaler() sc_col = ['pdays','previous'] mm_col = ['age','duration','day_of_week','balance','campaign'] sd_sc.fit(X_train[sc_col]) X_train[sc_col] = sd_sc.transform(X_train[sc_col]) X_test[sc_col] = sd_sc.transform(X_test[sc_col]) mm_sc.fit(X_train[mm_col]) X_train[mm_col] = mm_sc.fit_transform(X_train[mm_col]) X_test[mm_col] = mm_sc.fit_transform(X_test[mm_col])train 데이터에 대해서 fit한 것을 이용해 각각의 데이터의 수치형 변수들을 정규화 표준화 해주었다.
X_train_smote, X_valid_smote, y_train_smote, y_valid_smote = train_test_split(X_train_smote, y_train_smote, stratify =y_train_smote, test_size=0.25, random_state= 42) print(X_train_smote.shape, X_valid_smote.shape, X_test_smote.shape) print(y_train_smote.shape, y_valid_smote.shape, y_test_smote.shape)그리고 validation set을 train에서 따로 분리해내서 train,valid, test가 6:2:2 비율이 되도록 데이터를 만들었다
모델링
def XGB_objective(trial): param = { 'reg_lambda': trial.suggest_float('reg_lambda', 1e-3, 1.0), 'reg_alpha': trial.suggest_float('reg_alpha', 1e-3, 1.0), 'colsample_bytree': trial.suggest_float('colsample_bytree', 0.4, 1), 'subsample': trial.suggest_float('subsample', 0.4, 1), 'learning_rate': trial.suggest_float('learning_rate',0.001, 0.1), 'n_estimators': trial.suggest_int('n_estimators', 1000, 10000), 'max_depth': trial.suggest_int('max_depth', 3,10), 'min_child_weight': trial.suggest_int('min_child_weight', 1, 50), 'random_state':42 } model =XGBClassifier(**param) model.fit(X_train_smote, y_train_smote, eval_set=[(X_valid_smote,y_valid_smote)], eval_metric='error', early_stopping_rounds=100, verbose=0) pred = model.predict(X_test_smote) f1 = f1_score(y_test_smote, pred) return f1하이퍼 파라미터 튜닝에는 Optuna 프레임 워크를 사용하여 파라미터 튜닝을 자동화하였는데, 재현율과 정밀도의 조화평균인 f1_score가 높아지는 방향이 되도록 파라미터를 조정하였다.
sampler = TPESampler() study_xgb = optuna.create_study( direction='maximize', study_name = 'Xgboost Optuna', sampler=sampler ) study_xgb.optimize(XGB_objective, n_trials=100) print("Best Score:", study_xgb.best_value) print("Best trial:", study_xgb.best_trial.params)Best Score: 0.8770563273847584 Best trial: {'reg_lambda': 0.5755155546375601, 'reg_alpha': 0.8465963281729061, 'colsample_bytree': 0.8581150176716632, 'subsample': 0.976893743688381, 'learning_rate': 0.03283625746323232, 'n_estimators': 3206, 'max_depth': 9, 'min_child_weight': 14}100회 반복을 통해서 얻어낸 최적의 하이퍼 파라미터 값을 이용해 모델을 구축하였다.
evals = [(X_valid_smote, y_valid_smote)] xgb_c = XGBClassifier(n_estimators=3206, max_depth=9, learning_rate=0.03283625746323232, min_child_weight=14, subsample=0.976893743688381, colsample_bytree=0.8581150176716632, reg_lamba=0.5755155546375601, reg_alpha=0.8465963281729061, eval_set=[(X_valid_smote, y_valid_smote)], eval_metric='error', random_state=42, verbose=False) xgb_c.fit(X_train_smote, y_train_smote)y_pred_train = xgb_c.predict(X_train_smote) y_pred_test = xgb_c.predict(X_test_smote) result = pd.DataFrame({'acc' : [accuracy_score(y_train_smote, y_pred_train), accuracy_score(y_test_smote, y_pred_test)], 'f1_score' : [f1_score(y_train_smote, y_pred_train), f1_score(y_test_smote, y_pred_test)]}, index = ['train','test']) display(result)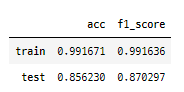
모델 예측 결과 test데이터에 대한 정확도는 85%, f1_score는 87%로 나타났다.
개인과제를 하면서 전처리 방법에 대한 고민을 심도 깊게 해볼 수 있었고 새로운 기법들과 라이브러리들을 알게 되었다.
원래는 KNN을 이용한 보간을 했었는데 관련하여 블로그도 있기는 했지만 범주형 데이터의 성격과 KNN의 거리 계산 알고리즘이 잘 맞지 않는다는 튜터님의 조언을 받고 다른 방법을 시도해보면서 많은 걸 배울 수 있었다.
모델 성능을 단순히 높이는 것에만 중점을 두기보단 데이터를 더 잘 이해하는 능력을 기르는 시간이 되었다.
'내일배움캠프(데이터 분석 부트캠프 1기) > 개인과제' 카테고리의 다른 글
<BI 대시보드> 개인과제(with Tableu) (0) 2024.02.29