-
<통계학> 통계적 가설 검정 -1 (귀무가설, 대립가설, p-value)데이터 분석 관련 공부 2024. 1. 22. 22:48
통계적 가설검정(statistical hypothesis)이란
통계적 추론의 하나로 모집단의 실제 값이 얼마가 된다는 주장과 관련해, 표본의 정보를 사용해서 가설의 합당성의 여부를 판정하는 과정을 의미한다(이군희, 사회과학연구방법론 법문사 2001 p367).
간단히 가설 검정 혹은 가설 검증이라고 부른다.
통계적 가설이란 특정한 주장을 모수를 이용해 나타낸 형태를 지칭한다.
ex) 한국 성인 남자 평균 신장은 172cm이다.
통계적 가설의 구분
이러한 통계적 가설은 귀무가설과 대립가설 두 가지로 나뉜다.
귀무 가설(영가설, Null hypothesis)
귀무가설이란 기존의 통념, 일반적인 개념으로 차이가 없거나 의미가 없는 경우의 가설로 이것이 맞거나 맞지 않다는 통계학적 증거를 통해 증명하려는 가설이다.
대립 가설(연구가설, Alternative hypothesis)
대립 가설 혹은 연구 가설이라고도 부르는데 귀무가설에 대립하는 명제이다. 보통 독립변수와 종속변수 사이에 어떠한 관련이 있다는 형태로 되어 있다.
어떠한 가설을 검증하는 데 있어서 귀무가설처럼 직접 검정을 수행하는 것은 불가능하기 때문에 귀무가설을 기각하는 반증의 과정을 거쳐서 받아들여지는 가설이다.
검정통계량
말 그대로 통계적 가설 검정을 위해 사용하는 통계량을 말한다.
검정 통계량이란 수집한 데이터를 이용해 계산한 확률 변수이며
확률 변수란 특정 확률로 발생하는 각각의 결과를 수치값으로 표현한 변수이다.
검정 통계량이라는 확률 변수를 이용해서 이러한 표본 통계량이 발생할 확률을 알 수 있기 때문에
이를 이용하여 계산을 하는 것이다.
검정 통계량을 통해 계산된 확률이 바로 p-value(유의확률)이다.
유의확률과 기각역
유의확률(p-value)란 앞서 설명한 검정 통계량을 통해 계산된 확률로
귀무가설이 참이라는 전제 하에 계산된 검정 통계량이 나올 확률이다.
따라서 p-value가 낮게 나타났다면 그러한 낮은 확률이 실제로 일어났다고 생각하기 보다는 귀무가설이 잘못되었다고 생각하고 이를 기각하고 대립 가설을 채택하게 되는 것이다.
일반적으로는 p-value가 0.05또는 0.01보다 작으면 귀무가설을 기각하게 되는데, 다시 말해 우연히 그러한 값이 나타났을 확률이 5%, 1%라는 것을 의미한다. 사회과학에서는 보통 0.05를 사용한다.
이렇게 설정한 p-value의 기준 값을 유의수준( α )이라고 의미한다. 유의 수준이란 조사에서 인정되는 오차의 수준이다.
다시 말해 유의 확률이 유의 수준보다 낮으면 귀무가설을 기각하는 것이다.
조사의 성격에 따라서 양측검정을 할 수도 있고 단측 검정을 할 수도 있는데 유의수준과 단측검정인지 양측검정인지에 따라 기각역이 결정된다.
단측검정
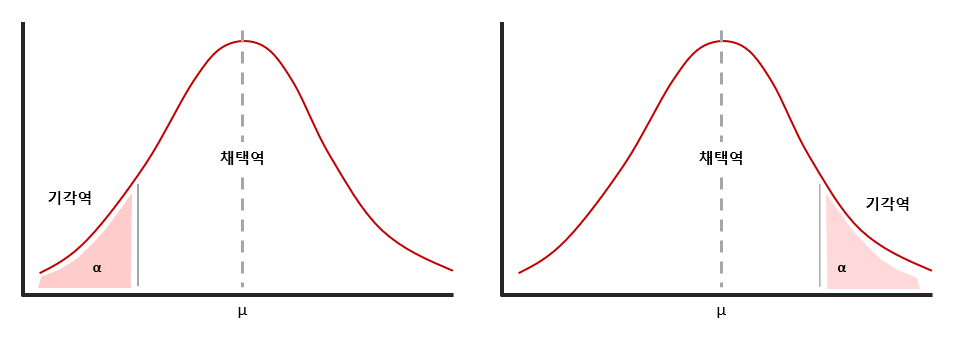
출처 :https://dlearner.tistory.com/36 단측 검정은 조사의 목적에 따라서 음의 방향, 양의 방향 중 한쪽만 살펴보는 검정이다. 대립가설이 어느 특정 기준보다 많거나 적은 지 한가지 측면으로만 검증한다.
양측검정
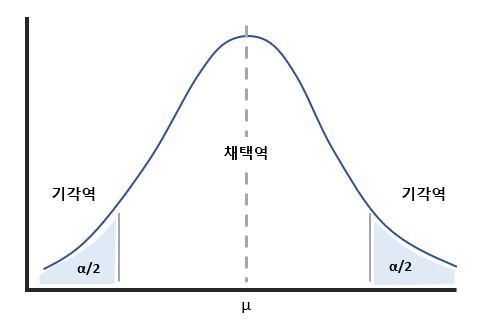
출처 : https://dlearner.tistory.com/36 양측 검정은 조사하고자하는 가설이 크거나 작다가 아닌 "같지 않다."인 경우라고 생각하면 된다. 따라서 작은 경우와 큰 경우를 모두 고려해야 한다. 정규 분포는 평균 중심 대칭 구조를 지니기 때문에 유의 수준을 반으로 나누어서 기격역을 설정하게 된다.
Refrences
'데이터 분석 관련 공부' 카테고리의 다른 글
<통계학> t검정(t-test) - 1 (1) 2024.01.23 <통계학> 통계적 가설 검정 -2 (신뢰수준, 1종 오류, 2종 오류) (0) 2024.01.23 <통계학> 큰 수의 법칙, 중심극한정리 (1) 2024.01.22 <Python, SQL> pymysql 라이브러리(with Pandas DataFrame) (0) 2024.01.12 <SQL : MySQL> RECURSIVE(재귀 쿼리) (0) 2024.01.09